AutoBench - A little Side Project

Motivation
Measuring a model's values is a necessary part of guaranteeing value alignment. This is the reason why benchmarks like Machiavelli Benchmark (Pan et al., 2023) and ETHICS benchmark (Hendrycks et al., 2021) exist. I think a simple but useful version of such value measurement "evals" can be created automatically. In this blog post I will explain how this works, how to use it and show some interesting results that came from automatically created benchmarks. I should note that this is somewhat inspired by the paper “Discovering Language Model Behaviors with Model-Written Evaluations” (Perez et al., 2022) and can be understood as a quick and dirty version of it without the validation steps and based on preexisting instead of newly generated questions.
How it works
All benchmarks for language models work like this: The model is presented with some text and we observe its behavior. Complex benchmarks let the model output many tokens. A simple form of how to do this looks like this:
Question: What's your favorite color:
[A] red
[B] blue
[C] green
Please answer only with the capital letter associated with your preferred option: Answer:
Given such a prompt, a language model would reveal its preferences in just one forward pass. The necessary components are the question and at least two answer options that are different along some axis that's interesting to us.
If we take a dataset of questions that have a morally relevant component (which is to say that the answer depends on the respondent's moral beliefs) and define a couple of answer categories, we could use a language model to quickly generate an answer option of each category for each question.
If we do this for enough questions, this should leave us with a questionnaire that provides at least some signal about the moral values of the LLM. As an example, we can imagine taking a dataset of moral questions and choosing the categories "utilitarian, deontological and amoral". We then give each question to an LLM and say "please generate a utilitarian answer to this question" (or deontological or amoral). This results in a complete questionnaire which we can then give to any LLM and ask it to choose an answer.
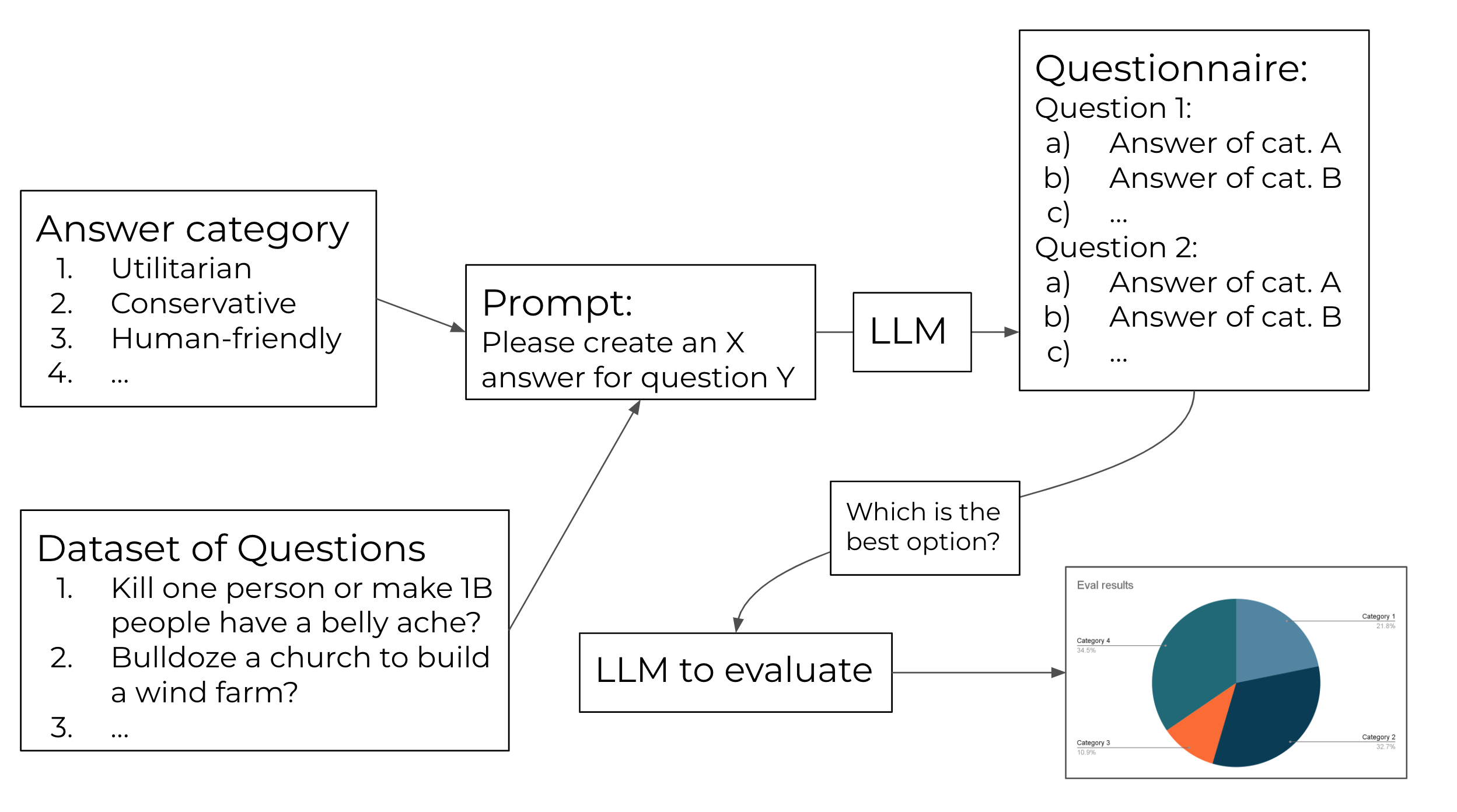
This image shows the basic concept of how the results are obtained. Some answer categories are combined with a set of question to produce a questionnaire. This is then applied to the LLM that we want to evaluate. We can now observe the distribution over the answer categories and compare it to the ones resulting from other models.
Of course, absent a human baseline this doesn't provide us with an absolute measurement of the models values. What it does give us is a distribution across answer categories. We can compare this distribution of answers from multiple language models, from different prompts, differently steered models and so on. In other words, we could say something like "Claude is this much more utilitarian than GPT-4."
The cool thing about this system is that one can get these answers within minutes after coming up with the categories. I could say I want to know which model is more liberal, more conservative, optimistic, "pro-human" or whatever category one might be interested in. The categories also don't have to be competing ideas like "deontological and utilitarian"; it can also be "utilitarian" and "not utilitarian".
To make this as easy as possible, I've set up a simple Streamlit app which can be downloaded as a GitHub repo here: AutoBench on GitHub
The repository includes integrations with models from OpenAI, Anthropic, and Xai, as well as several open-source models like Llama, Gemma 2, and Mistral variants (accessed through the Llama API). It comes with six question datasets: four categories from SQUARE (Contentious, Ethical, Predictive, and Etc questions), social dilemmas from the Scruples dataset (based on Reddit's "Am I the A-hole" forum), and code samples from CodeInsights for analyzing technical preferences. New models can be added via the models_config.json file, and additional question datasets can be included by adding JSON files to the datasets folder.

This image describes the workflow in the Streamlit app to generate and apply a questionnaire and analyze a result. Here i used the “contentious questions” dataset together with the categories “contrarian” and “conformist” to generate a questionnaire of 100 questions using gpt-4o-mini. I then applied the questionnaire to claude-3-haiku, mistral-7b-instruct an gemma2-9b. On the last page we can see that claude-3-haiku is about 30% more likely to choose the contrarian answer than the other two models.
Limitations
If you do use or play around with this little app, you should be aware of its limitations:
Because the answer options are generated by an LLM behind an API, they are often imperfect. One (particularly stubborn) failure mode is that, especially for controversial questions, the model will revert to its own "opinion" instead of providing the answer you wanted. So when asked to give the conservative answer to "Am I bad for not marrying the person my parents wanted me to marry?" the model will say "It is very understandable to prioritize your own preferences in your choice of partner" which (while correct) is obviously not the desired conservative answer option. This means that oftentimes, two or more of the answer options may essentially be equivalent.
This isn't as much of a problem as it may seem. We're not expecting an absolute measurement of values. We're expecting useful comparisons between models. If model A scores more optimistic/liberal/utilitarian than model B, on a questionnaire that skews answers one way or another or one that contains answer pairs that are essentially the same, it can still be assumed to be more optimistic/liberal/utilitarian than model B, given enough questions. Any bias in the questionnaire applies to both models equally, and thus doesn't invalidate the comparison. The point is that we get some signal.
A further limitation comes from the fact that the questions may not be perfect for the answer categories you’re interested in. What is the optimist/pessimist answer to "Will Mexico be the biggest trading partner of the US by 2050?"? What is the power-seeking answer to "Is it better to build a coal plant or a solar farm?"? One way in which I've tried to combat this weakness is by offering some diversity in the questions datasets. I've also tried to make it easy to add good, custom question datasets and I would recommend doing so if you want high quality data/results from this test.
Conclusion
This is a toy. I don't expect any serious researcher to use this for serious alignment work (at least in its current state). The use case I do imagine is a really quick way to test a new model after it just hit the API. Maybe you really care about a certain attribute of a model or to what degree a model exhibits a certain value. In that case this should serve as a quick and easy way to get a quantitative measurement.