Transformer Decompiler - TraDe

February 2024Introduction
This blog post describes my motivation for and the nature of my research project called “Neural Decompilation of Tracr Transformers”. At first, I go into my motivation for approaching the problem of interpretability from this angle after which I go into the technical details of what I did. Here is a quick tldr.
Interpretability is hard, but if we manage to “solve it”, it might give us fundamental advantages that other approaches to AI safety are unable to provide.
What makes interpretability hard is the irreducible complexity of a neural networks weights and activations. However, if we look at these weighs and activations as a new modality like images and sound, it seems quite intuitive that we could just task another neural network with their analysis.
The big obstacle in attempting this is the training data. We have almost no input-output examples for the task of “explaining a neural network”. My work is about seeing what happens when we use an approximation of such pairs, created by compiling so called “RASP programs” into functional transformer weights, to train a network, capable of analyzing these weights.
In the post i explain in detail, how the training data is produced, what the decompiler network looks like, how i feed weights into it and get it to produce RASP programs and how well it all ends up working in the end. The important number for that last point is that the model successfully “decompiles” 73% of all inputs, which is surprisingly high.
I finish by detailing the limitations of this approach in it’s current form.
Interpretability
The way in which interpretability is hard
Neural Networks are “black boxes”. What do we mean by that? It’s an interesting question because unlike with human brains, we have unhindered access to every process happening in the neural net. We know, with arbitrarily high accuracy, every weight, bias, activation and connection. But we still view them as “inscrutable”. Why?
Originally I had a metaphor here about a sandstorm where the components are also simple but predicting the big-picture-future is hard. I was not satisfied with this metaphor. You could compare this neural network black-box problem to the human body where we understand all the chemical reactions but can’t conclude a human’s behaviour from them, but that’s also not a good comparison, since we also don’t have the ability to detect all of those chemical processes with arbitrary precision, while, as mentioned, we can measure everything happening in a neural network very precisely.
The truth is that this is a pretty unique situation. Our understanding is really just made difficult by the irreducible complexity of the causal connections within the neural networks. This difficulty is not a matter of the complexity of the process's components. The number of components and what emerges from their interactions is what complicates things. It complicates it to such a degree that it makes it impossible to grasp the bigger picture, even if you know every detail of the „smaller picture“.
This is what we‘re facing with neural networks. They‘re a huge salad of numbers and vectors. Not positions, and velocities of sand grains or proteins and cells but the strengths of connections between neurons, a neuron’s activation function or the magnitude of their activations. From that, we try to predict plans, goals and other things that might help us determine whether a neural net will produce beneficial outputs or even how we might change the network so that it is more likely to do so.
What‘s so great about interpretability?
If this is such a hard problem, why not just approach AI safety from a different angle? Good question. First of all, I‘m not suggesting we shouldn‘t. It seems pretty plausible that other approaches might come out on top, maybe because we make a lot of progress there or because interpretability turns out to be too hard. I would honestly not be surprised if the latter turned out to be the case. Maybe the mechanism from which superior intelligence emerges gives rise to such intelligence exactly because of its complexity. Maybe the ability to cope with the complexity of a task is the result of internal complexity. In the same way, a complex map is a better depiction of complex territory.
The reason I think we should still attempt to crack interpretability is that it offers some unique advantages over other AI safety approaches. AI safety is fundamentally about GI safety, that is how to deal with Greater Intelligence. As long as the AIs stay as dumb as they are now, controlling them will remain less relevant and much easier. But controlling a greater intelligence is hard. Think dogs, chimps or even kids trying to control adult humans.
If all we can look at are the outputs of a system much smarter than us, we will find ourselves on the side of the chimps. The losing side. But if we can access an AI’s internals, its thoughts, plans and goals we might level the playing field a little in a way that no other approach to AI safety could.
In defence of fighting fire with fire
So, this is a problem that requires the understanding of a huge number of patterns and the processing of a lot of data in a modality unfamiliar to us? Great! We have a thing for that. It’s called deep learning.
I know, I know this makes the problem recursive. How can we trust an AI’s analysis of another AI? That’s a good point. I guess I do trust simple narrow AI. Neural nets can be too simple to be the host for dangerous intelligence. Maybe, we can make a neural net simple enough for it to remain uncorrupted by advanced intelligence and the agentic dynamics it brings but capable enough for it to still be able to decipher the neural networks of the advanced, dangerous AI. I think it’s worth a try.
My work
The Idea
So we want to get AI to do our interpretability work. How do we go about that? The way to get an AI to do something, to give it a new ability is to train it on a lot of examples. That represents a problem for this particular use case. There are very few examples of neural networks paired with descriptions of their internals. This is even more true for transformer neural networks, which are of special importance because the transformer is the architecture powering the current wave of AI progress. Pretty much the only example of a fully described transformer (that I know of) is the one trained to do modular addition and painstakingly analysed over the course of weeks by Neel Nanda. To train an AI we need at least 10s of thousands of examples. Generating a training set manually is not an option.
Obviously, we also can’t generate the training set automatically, by automating the description of trained transformers. This automation is what we need the training set for in the first place.
But if we just need the pairs, why not start with the description and make the transformer based on it? This sounds much easier. In fact, there exists a recent paper that does exactly this. It introduces a method called tracr, which takes so-called RASP programs (a programming language meant to be computationally equivalent to transformers) and turns them into transformer weights, that do the same thing as the program. Tracr is an acronym that stands for TRAnsformer Compiler for Rasp.
If we view a rasp program as a description of a transformer’s internals, which is not unreasonable, this gets us the transformer-description pairs we were looking for.
The Nitty Gritty

The core concept of TraDe
So let’s get specific. From here on the blog post will get somewhat technical. You have been warned, proceed at your own peril.
1) Generating Programs
The first step, the generation of the random RASP programs, represents the first problem. It may sound somewhat easy at first but we can’t just chain up random components of the RASP language. The resulting programs still need to actually work.
A few years ago I watched the comedy version of the British tv game show “Countdown”, where one of the tasks is to come up with a way to combine a set of smaller numbers in a calculation that results in a given bigger number. I wanted to write a program that solves this for me. But being lazy, I just ended up writing a brute force program. Brute force in this case just means that I generated random calculations until I found one that hit the target. This worked well and was surprisingly fast by the way.
I ended up using pretty much the same algorithm to generate valid but random programs here. It’s based on a pool of operands, the contents of which are randomly chosen to be the inputs for randomly chosen functions. The output of these functions then gets added back into the pool of available inputs. If you want the program to converge to a single output, you simply remove the operands from the pool of available inputs. Since most functions have more than one input and only one output, this results in a shrinking pool of possible inputs. Once there is only one operand left, this is designated as the output and the program is complete.

An illustration of how new programs are generated. 1, 2 and 3 represent the steps involved in generating a new line of code(/a new node in the computational tree). These steps are repeated until the Pool of available inputs only contains one variable.
I think this is not too dissimilar from how we, as programmers, write programs. There are some variables available for us to process with a set of functions which then produce new variables. This intuition is part of what leads me to believe that this method covers the space of possible programs quite well.
2) Compiling the Programs
Since Tracr is available as a codebase on Git Hub, this required much less creative input from me. However, there were still some problems. I first noticed that a small minority of the programs resulted in HUGE models. Since the number of weights in the models I generated would influence the size of the eventual decompiler model, this was a problem. I ended up overproducing by about 10% and just removing the largest 10% of transformers.
Another issue I encountered is that there are still some gaps in Tracr. Certain RASP programs can’t be compiled for various reasons (like the aggregation of float values with a selector with more than 1) or cause the compilation to take an unacceptably long time. To deal with this I (being lazy) simply implemented rejection sampling.
Since a majority of the generated programs did get rejected, I am a little worried that the space of programs that do end up making it to the dataset doesn’t cover enough of the whole space of possible programs. But I guess this is a limit, inherent to the concept. We can’t really decompile transformers that were not compiled (correctly) in the first place.
After having the program and the corresponding transformer weights I was then faced with the question of how to feed them into a neural net (the decompiler).
I tested quite a few options but, frustratingly, none of the options worked better than the first thing I tried, which worked in the following way:
The programs were split up into lines, with each line producing a new variable using a function and a set of inputs. Since the max number of inputs for functions is three, I simply defined an “empty” token which would appear if a function requires less than 3 inputs.
So each line was represented by 4 tokens each of which was just a one-hot encoded vector representing a number between 0 and 31 (31 being the empty token). This way, the program could be reproduced by the decompiler one token at a time, which would then be grouped into lines.

The process of tokenising the RASP program
Representing the transformer weights in a vectorised form was a little less intuitive because, unlike programs, weights are not organised sequentially. I took a look at vision transformers, which also organise non-sequential pixel data into tokens and work quite well in the end. This gave me the confidence to proceed with a matrix-based tokenisation scheme. This basically means that each weight matrix in the transformer is flattened into a vector, modified with some metadata (what kind of matrix it is (value, query, key, MLP or encoding), which layer and head it is in and so on) and padded to a uniform size. This ends up working quite well.

The process of tokenising the weights of the Tracr Transformers
3) Training the Decompiler
With this dataset, we can now train a neural network. But what kind? As a kind of proof of concept/baseline/sanity check, I first built a basic MLP network and trained it on 10k samples on my laptop. To my honest surprise, this worked a little.
I first generated a lower complexity data set. I excluded the functions rasp.Map() and rasp.SequenceMap() from the possible functions and limited rasp.Select() to only use rasp.Comparison.EQ as a comparator.
On this dataset, the MLP prototype reached about 15% sequence accuracy after multiple thousands of epochs. I tried many different MLP architectures but none of them resulted in much better performance. Probably in large part because I naively kept the dataset at 10k samples.
To improve this I looked at different architectures. I thought this was a little like a translation problem, but instead of translating between languages, we are translating transformer weights into rasp code. Considering this framing, I thought I better jump on the transformer hype train. Someone in a coworking space in Zürich suggested that I look at it like OpenAI’s Whisper model, which is also translating between modalities. So I implemented an encoder-decoder transformer using pytorch.

Encoder decoder architecture of the decompiler model
To express how well it worked, I need to explain some terminology that kind of came up with for myself and am not sure is standard. Unlike the MLP prototype, which predicted the whole code in one forward pass, this transformer model only predicts one token at a time. This means that we need to make a distinction between the following metrics:
The most important metric that I measure success by is what I call “sequence accuracy”, this represents the fraction of inputs, for which all of the reproduced tokens were correct. This metric has an exponential connection with another metric called “token accuracy” which is the fraction of tokens the model gets right. This needs to be really high since:
sequence accuracy ~= token accuracy ^ tokens per sequence
There is also a difference between the sequence accuracy in autoregressive generation and in training/validation. Autoregressive generation means that mistakes might cause a mistake in a subsequent forward pass, which can severely impact performance. In this case:
sequence accuracy ~= token accuracy ^ (((tokens per sequence)^2 + tokens per sequence) / 2)
I’m unsure about how to handle this distinction, but after talking to a more experienced researcher about it, I guess using the non-autoregressive sequence accuracy, where the decoder input is always correct, is okay.
After getting the hang of it, I got the transformer to a sequence accuracy of 25% on the simplified dataset pretty quickly. I then spent more than a month experimenting with different model architectures and tokenisation schemes. None of them yielded reliable improvements. Most actually degraded performance.
Only two changes really made a difference. One was simply increasing the size of the dataset from 30k to 120k samples. This got the accuracy up to 34%. The second improvement was filtering out the samples where the model didn’t compile correctly. This improved the accuracy to 40%. The lesson behind this seems to be what everyone else has already said. Data quantity and quality are what make or break transformer training.
Since this process took multiple months, I thought it was time to move to the full-complexity data set even though I didn’t reach my goal of 70-80%. I set the goal so high because I was under the impression that adding the two other RASP functions (Map() and SequenceMap()) and especially all the different lambda functions (which Map() and SequenceMap to the data would make the task way, way more complicated and thus degrade the performance of the model by many factors.
Luckily, I was wrong. While the performance got worse, it wasn’t nearly as bad as I expected. On a first test-training run with just 50k samples, the model achieved around 15% sequence accuracy. It also responded really well to more data and over the course of about a week, I increased the dataset size to about 550k samples which resulted in a sequence accuracy of up to 30.6% sequence accuracy.
Evaluating the Decompiler
I find it quite satisfying to pick apart how the model performs on different metrics. We know that the sequence accuracy is 30.6% in non-autoregressive generation. Interestingly it only drops to 26% in autoregressive generation which suggests at least some robustness to faulty decoder input. If we look at the validity of the code that’s output by the model the non-autoregressive mode produces runnable code, 60% of the time. Running the code that’s output by the model also allows us to interrogate whether the predicted code is functionally equivalent to the ground truth code. We know that to be the case for the 30.6% where the code is literally equal to the ground truth, but, when run in non-autoregressive mode, an additional 11%, the model produces code that is functionally equivalent (represents the same input-output relation) to the ground truth.
At first, I thought that these additional 11% was just because a significant fraction of the function just represents the f(x) = [None]*len(x) function, but after some investigation, the model appears to be able to recover the more complex input-output relations.
However, when run in autoregressive mode a total of 91% of all outputs are compileable and, remarkably, a total of 73% of the model outputs, are functionally equivalent to the ground truth and thus a valid decompilation. They mostly differ from the ground truth in the sequence of operations or in lambdas, because those can be equivalent depending on the input space.
This, I think is pretty strong evidence that the decompiler model has actually learned a mapping from the transformer weights to equivalent rasp code.
There is ambiguity in RASP code, meaning you can write the same program in multiple different ways. For example, if you define two variables that are independent from each other, it doesn’t matter which you define first. In non-autoregressive mode, the model doesn’t know which of the two independent variables it defined first because it only looks at the previous tokens of the ground truth, instead of its own previously generated tokens.

These programs would be identified as a faulty reproduction because the literal program is different. But they are functionally equivalent, meaning they represent the same input-output relation. The var4 variable is produced by a select_width() function, which only outputs values equal to or greater than zero. When applied to such values, the function abs(x) and x if x>0 else 0 are equivalent.
Suppose we maintain that the relationship between token accuracy and sequence accuracy is exponential with sequence length, and we now take the 73% of sequences to be correct (defining “correct” as exhibiting the desired function”). We can calculate that the implied token accuracy is 98.9% (which I’m allowing myself to round up to 99%) which is something I’m very happy with.
I also tracked how well the model was able to reproduce lines of a certain function. Though it performed better on functions that appeared more often in the dataset, this relationship isn’t linear, suggesting that there are functions that are harder and functions that are easier.

A plot showing how often the model identified each function correctly in relation to how often they appeared in 1000 randomly selected programs.
I should also mention that the programs that the model made mistakes on are not wrong in their entirety. In fact, they are often mostly correct and still provide insight into what the transformer that the code was decompiled from actually does, or at least how the information flows through it.
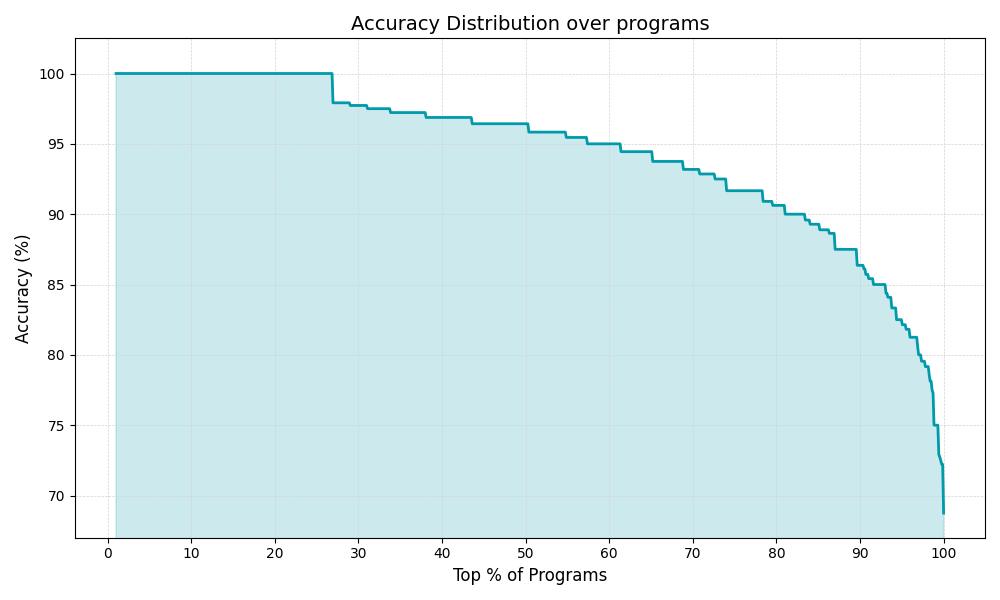
This shows how much of the program the model got correct. For about 30% of programs it’s 100% accuracy. So you should read this plot as x% of programs were reproduced by the model with at least y% accuracy.
Limitations
At the beginning of this post, I spoke about the value of interpretability and the importance of automating it. I want to make it very clear that what I describe in the above technical part of this post is not that. Not even close. This is a push towards a draft of a solution in a toy environment. But I guess I kind of expect that that’s how a real solution for the real problem could start or be pushed closer towards being accomplished.
Here is a list of problems that keep this technique/model from being applied to the real world.
1.Tracr transformers are super unrealistic
If you look at the weight matrices of a tracr transformer, aka the input of the decompiler model, you will find some clear geometric patterns like lines or triangles in an otherwise sparse matrix. The weights are very cleanly organised. There are no weird phenomena like superposition. This is very much unlike weight matrices of neural networks that were “organically” trained on realistic data. Those look messy and noisy, almost random. This is one of the reasons why we cannot expect this model, and maybe even this technique of creating a decompiler model to work on trained networks. There are a few approaches that may be able to deal with this somewhat but that’s a story for another day.

A tracr transformer weight matrix vs the weight matrix of a trained transformer
2. Decompiler to Decompiled scale
My decompiler model is roughly three orders of magnitude larger in terms of parameter count than the models it is capable of decompiling. If this ratio (or anything close) is needed for the decompiler to be successful that also completely rules out application to frontier, proto-AGI models (which is what I’m interested in). Frontier model training is already very expensive. The upcoming models, where strong interpretability might actually be the deciding factor in us being able to align them, are likely to cost at least billions to train. We can’t expect frontier AI labs to then also build a much bigger and therefore much more expensive decompiler model (maybe we should be able to expect that considering what’s at stake. What I mean is it’s not realistic). Here too, there are approaches attempting to mitigate this problem, but they accept compromises which I’m not sure are acceptable.
3. RASP is not really Interpretable either
One of my criticisms of the Interpretability field is that not enough work is being done to formulate a good end goal to aim towards. By end goal, I mean a concrete answer to the question “What do we wanna know about models and how do we want this represented”. The latter half of this difficult question is not to be underestimated. Merely representing a goal or plan in natural language, is not optimal, as natural language leaves a lot of room for ambiguities. It would for example be nice to represent a goal as a vector in “goal space” so that we could then measure distance to our goals or a desirable goal along various axes. The same goes for plans. I have of course no idea what the axes of these spaces should be, or whether such a representation is even possible.
The outputs of my decompiler model are represented as RASP code (actually a binary representation of a computational graph that is then translated into RASP code). This is not very interpretable. To extend the decompiler analogy, going from model weights to RASP is like going from binary to assembly code. It certainly makes the algorithm more readable, but on a large scale, say a billion lines of code, we are still far from an actual understanding of complex characteristics like goals or plans. I think this might not be as much of a problem as the rest. Going from weights to rasp is certainly a step in the right direction. It’s just that we need to build further abstractions on top of the rasp output.
Conclusion
I really enjoyed this research project. It required me to learn how to implement different things. Generating the data and getting it into a form in which it can be fed into and produced by the models was very interesting. But I learned a lot about transformer training by having to train a transformer on these two new modalities. There were no existing recipes as there are in language models or computer vision. So the trial and error process of what works and what doesn’t was full of teachable moments.
I think this concept has a future in some form, but it seems very obvious to me that continuing to train on plain tracr transformers is not the way to go. I can also imagine that, instead of having the intermediate RASP stage on which further abstractions can be built, it would be better to directly output the interesting characteristics of a model. I think being able to reproduce the rasp code heavily implies that the detection of some characteristics is very much possible. This might also allow us to shrink the decompiler model, which could mitigate the scale problem.
Like I said in the introduction, I’m not sure about whether interpretability is the right way to go about AI safety. My next project will likely be in the realm of evals. But if interpretability is ever going to be useful, I’m almost certain that it will be because we have some automated way of translating a model’s internals into a human-readable modality.